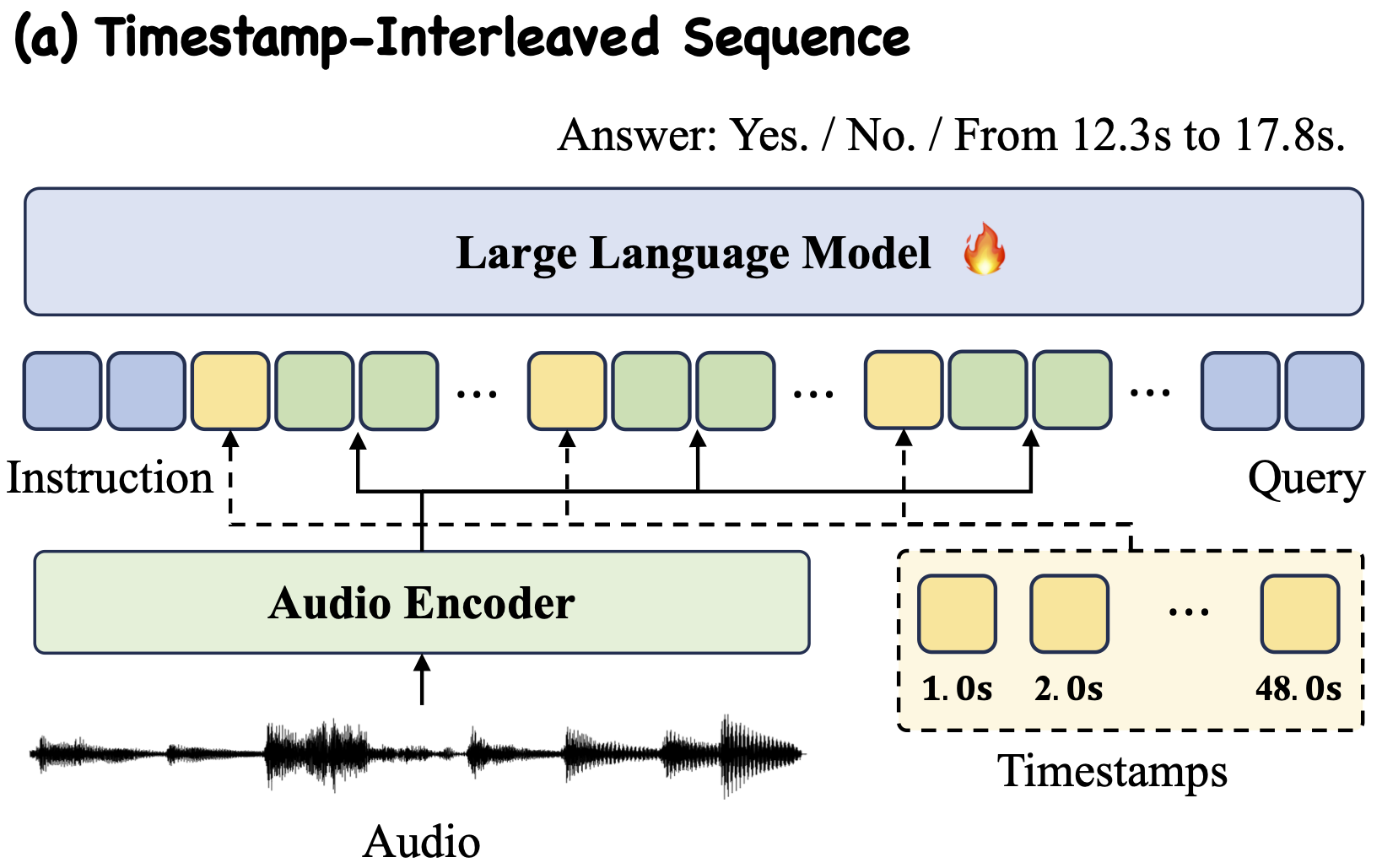
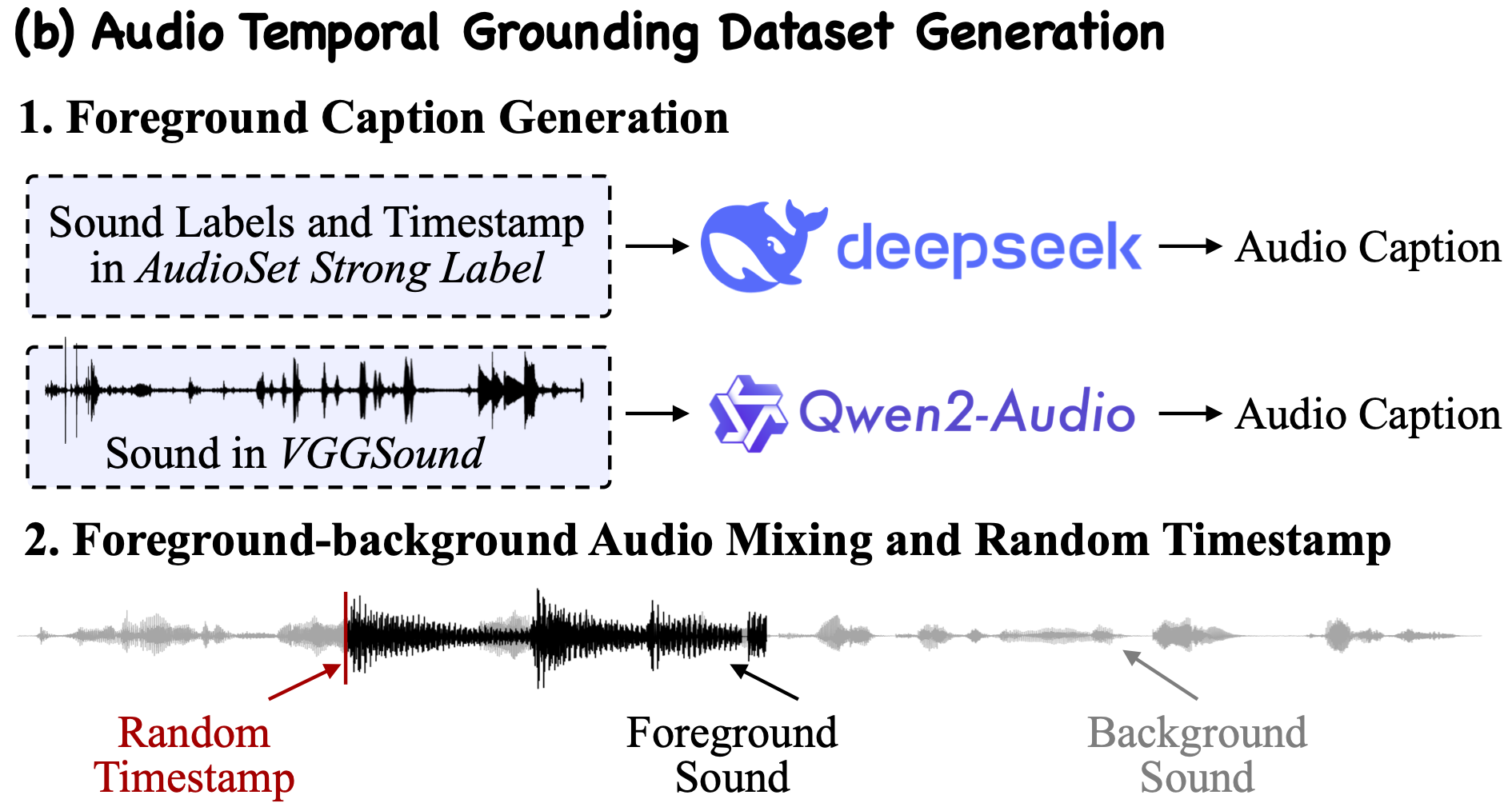
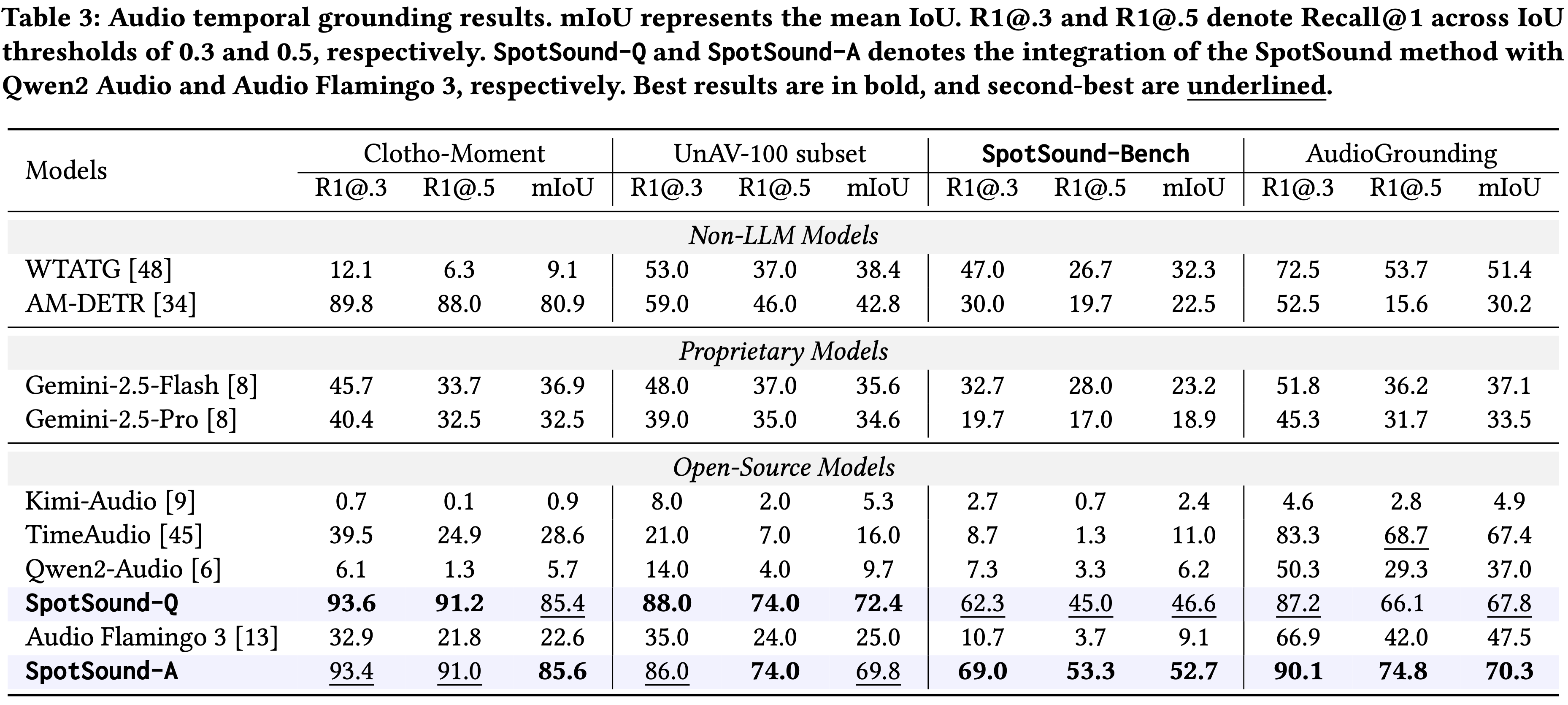
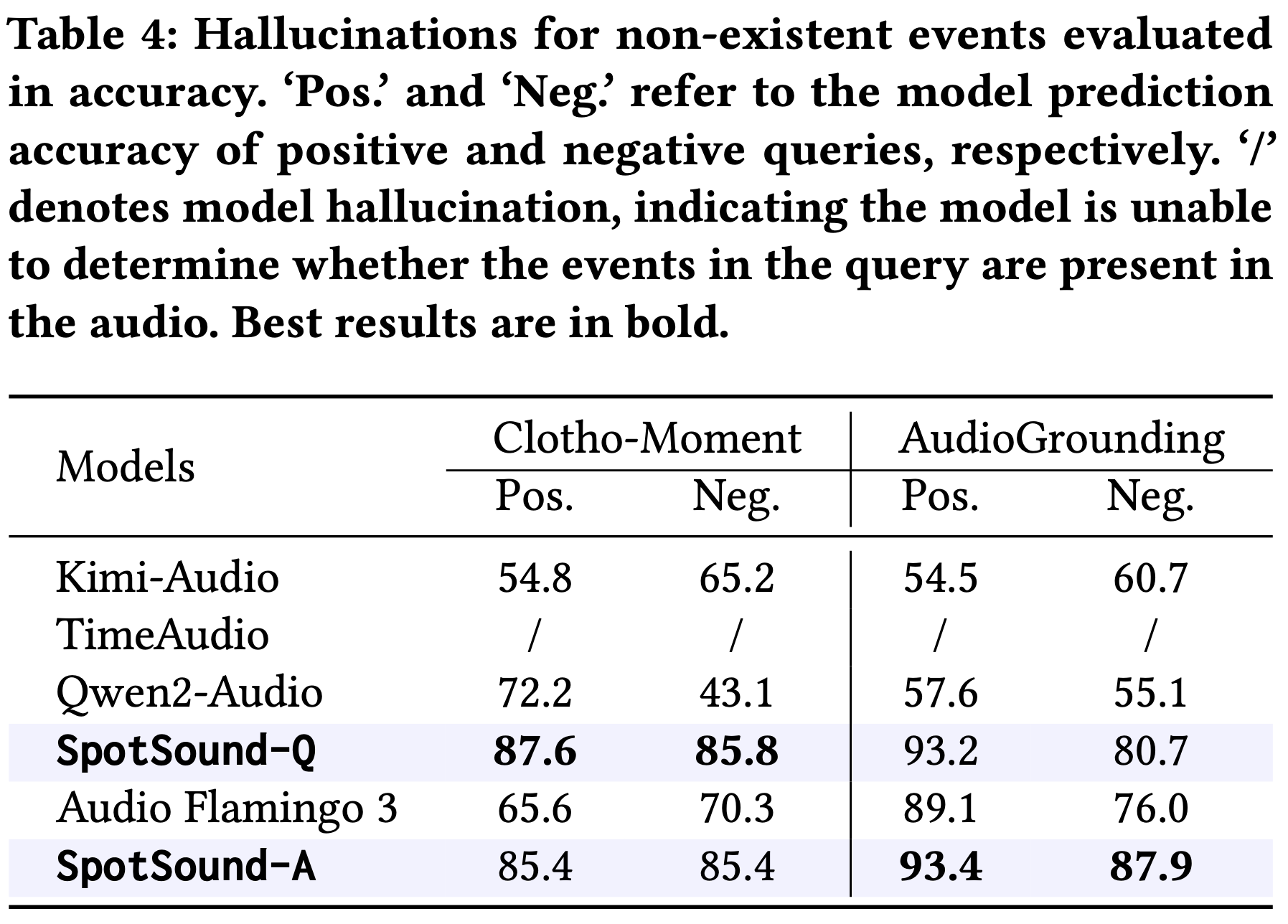
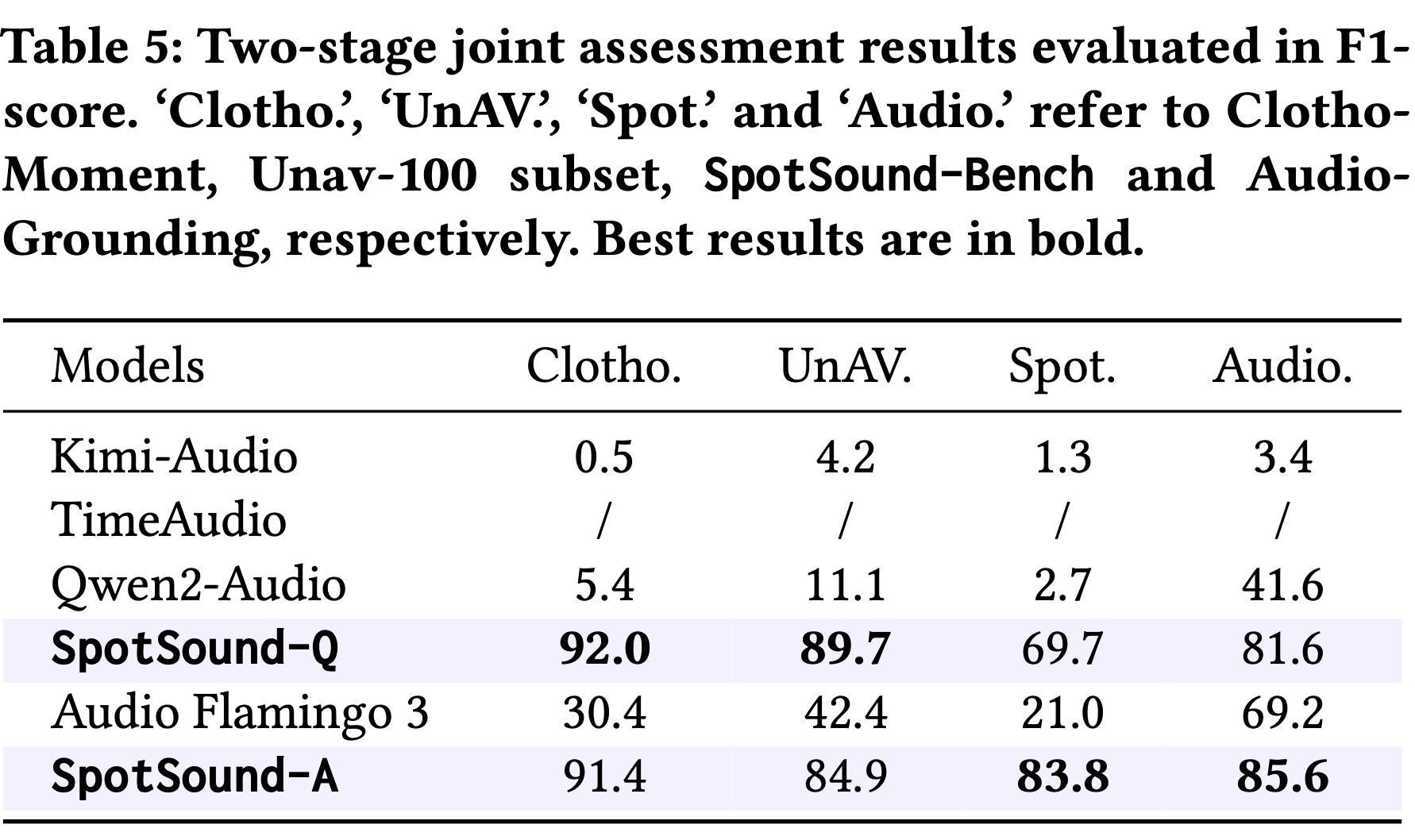
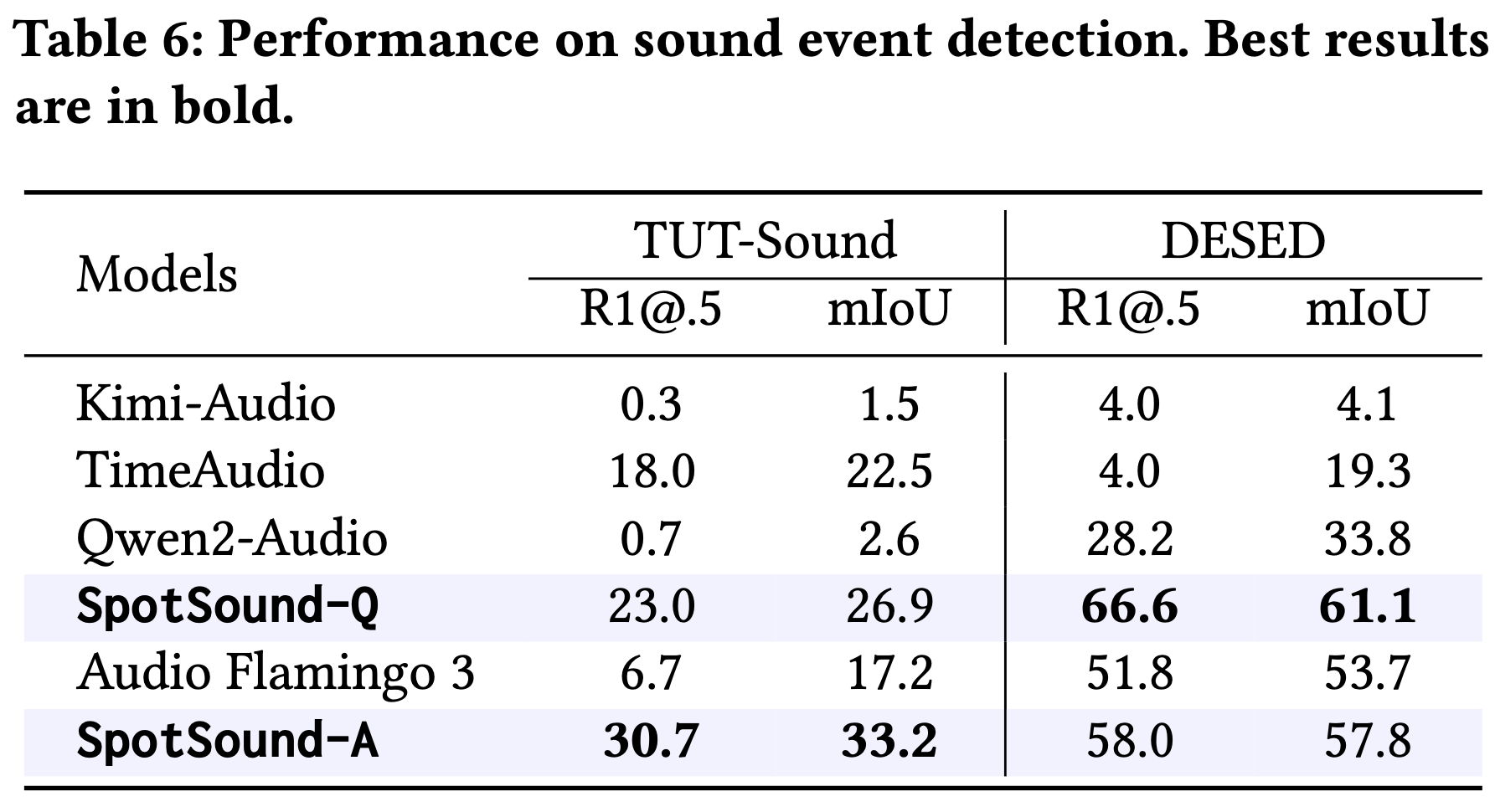
Large Audio-Language Models (ALMs) have recently demonstrated remarkable capabilities in holistic audio understanding, yet they remain unreliable for temporal grounding, i.e., the task of pinpointing exactly when an event occurs within long-form audio. This limitation stems from two factors: training data dominated by clip-level supervision lacking precise timestamps, and benchmarks that fail to simulate real-world scenarios where short events are obscured by dense background sounds. In this paper, we introduce SpotSound, an audio language model designed for grounding audio events. SpotSound incorporates a novel training objective, specifically designed to suppress hallucinated timestamps for events absent from the input. Additionally, we present SpotSound-Bench, a challenging temporal grounding benchmark where target events occupy less than 10% of each clip, creating a rigorous ‘needle-in-a-haystack’ evaluation. Experiments demonstrate that SpotSound achieves state-of-the-art results on temporal grounding benchmarks while maintaining robust performance across general downstream audio-language tasks.