|
I am a PhD student at College of Computer Science and Technology, Zhejiang University and an intern researcher at Shanghai AI Laboratory, supervised by Prof. Weidi Xie. I obtained my MSc in Shanghai Film Academy, Shanghai University. I earned my bachelor degree from School of Software, Yunnan University. My research direction is multi-modal representation learning, omni-modal understanding and audio spatio-temporal grounding. |

|
|
|

|
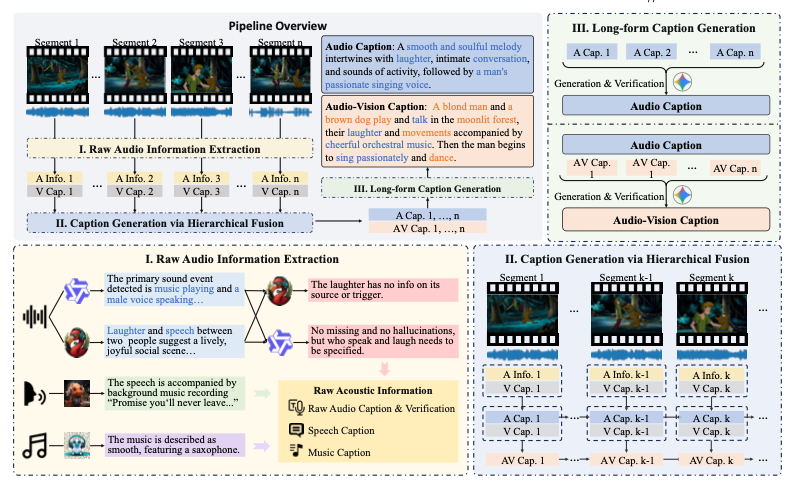
Luoyi Sun, Xiao Zhou, Zeqian Li, Ya Zhang, Yanfeng Wang, Weidi Xie ACM MM, 2026 ArXiv / Webpage / Benchmark / Code / Model Utilize large audio-language models for audio temporal grounding and construct a challenging needle-in-a-haystack benchmark. |
|
Kaiying Yan, Luoyi Sun, Xiao Zhou, Weidi Xie Submitting to ECCV, 2026 Introduce AVDC dataset and AVDC-QA-CoT with two-stage training to advance audio-visual omni-modal understanding. |
|
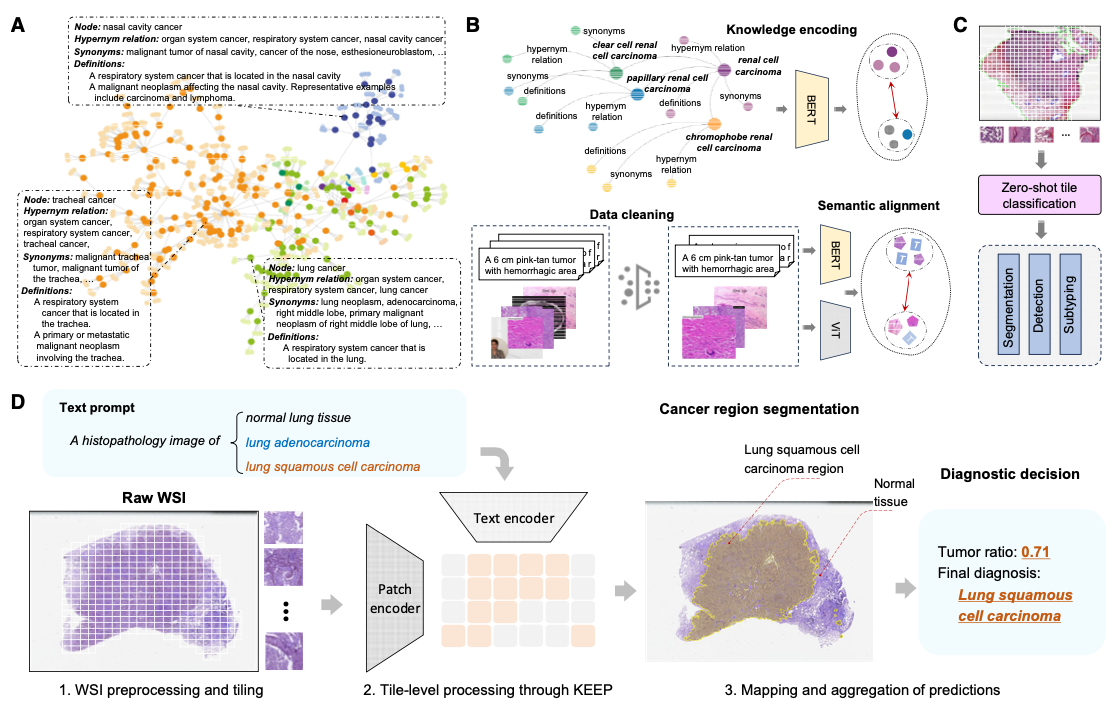
Xiao Zhou, Luoyi Sun, Dexuan He, Wenbin Guan, Ge Wang, Ruifen Wang, Lifeng Wang, Xiaojun Yuan, Xin Sun, Ya Zhang, Kun Sun, Yanfeng Wang, Weidi Xie Cancer Cell, 2026 ArXiv / Webpage / Dataset / Code / Model Integrates disease knowledge into pathology vision-language pretraining for cancer diagnosis. |
|
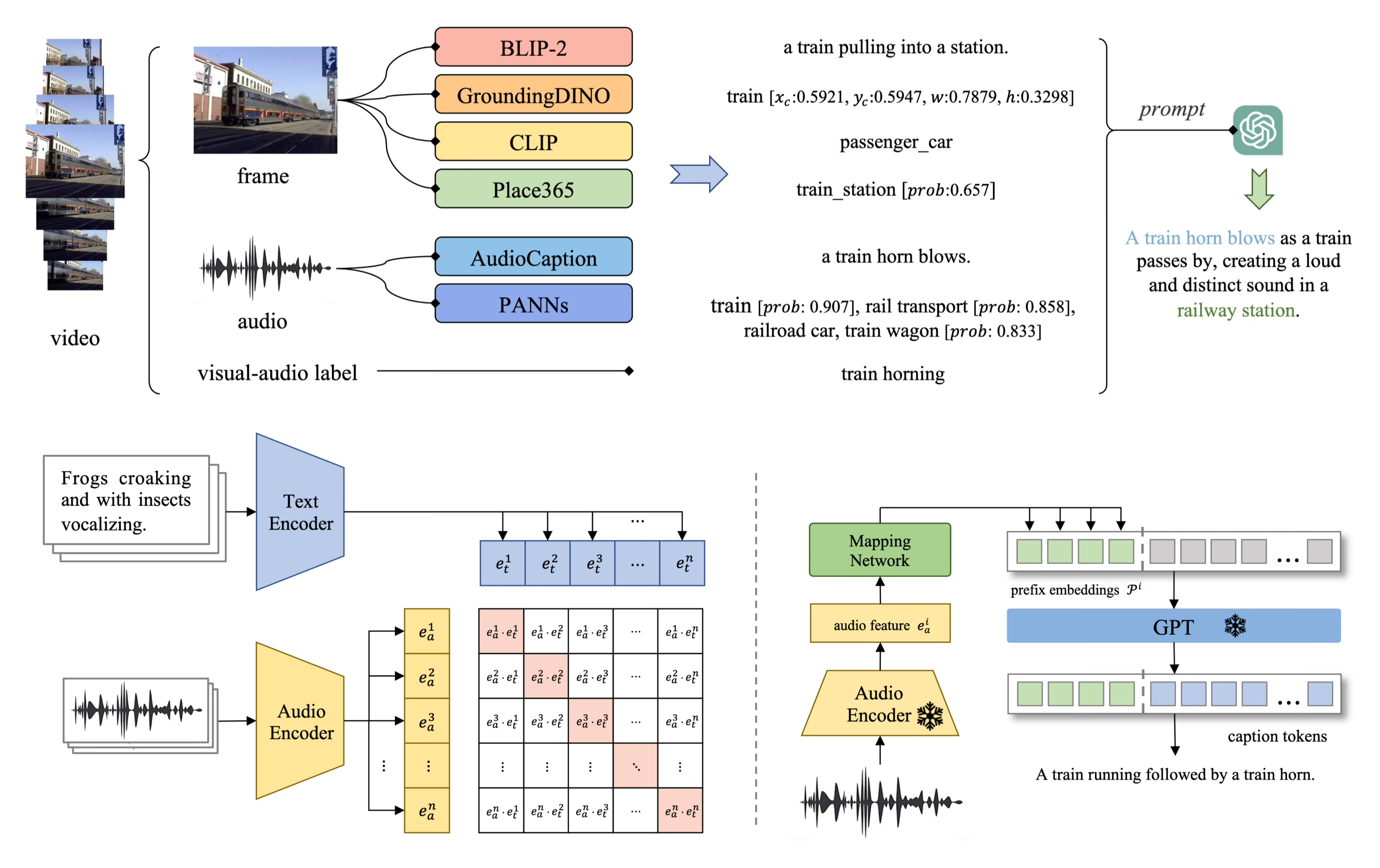
Luoyi Sun, Xuenan Xu, Mengyue Wu, Weidi Xie ACM MM, 2024 ArXiv / Webpage / Dataset / Code / Model Utilize computer vision tools to generate a large-scale, high-quality audio-language dataset. |
|
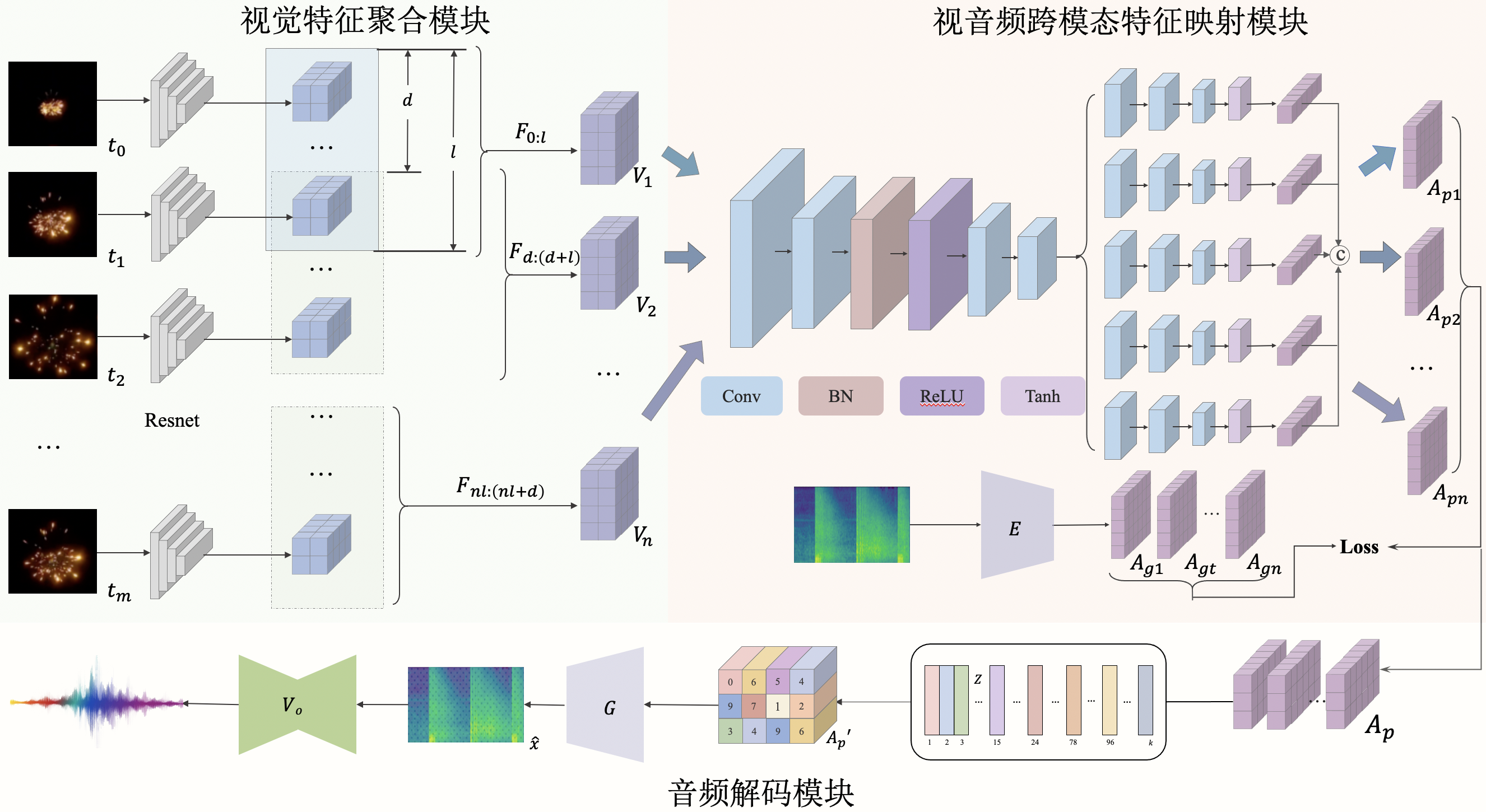
Zhifeng Xie, Luoyi Sun, Yuzhou Sun, Chunpeng Yu, Lizhang Ma CADCG, 2022 New framework for high-quality sound generation, matching to silent videos in content and timing alignment. |
|
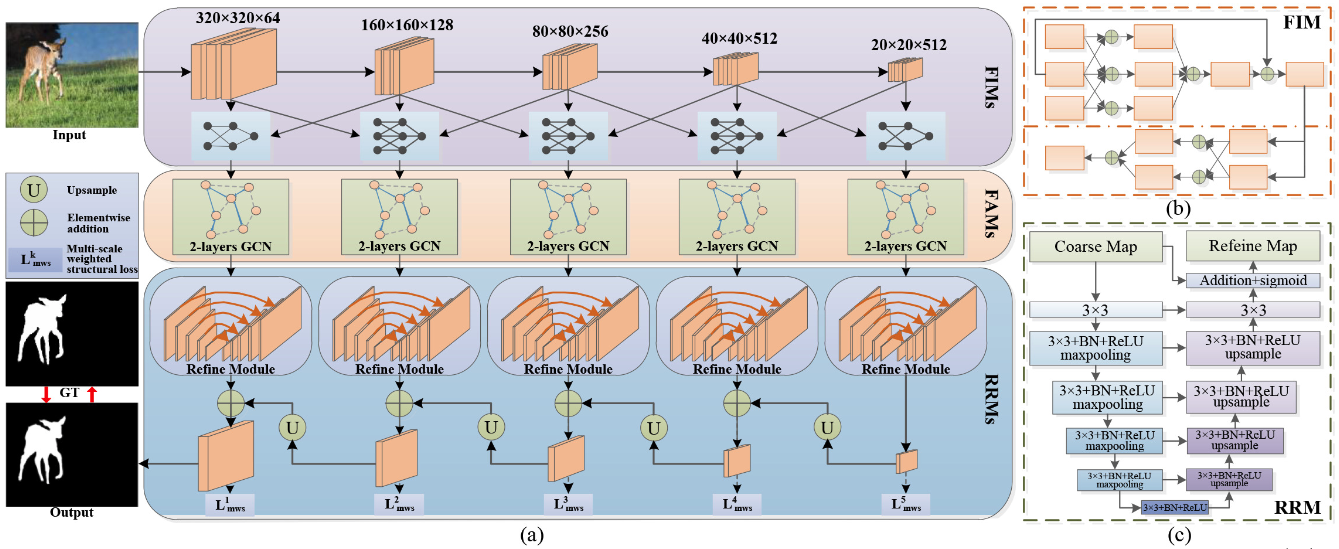
Wenqi Che, Luoyi Sun, Zhifeng Xie, Youdong Ding, Kanli Han ICIP, 2021 Proposed the multi-scale graph convolutional interaction network (MGCINet), and get the SOTA on five benchmark datasets. |
|
|
|
|
|
|
|
|